

 中文
中文CyberGPT



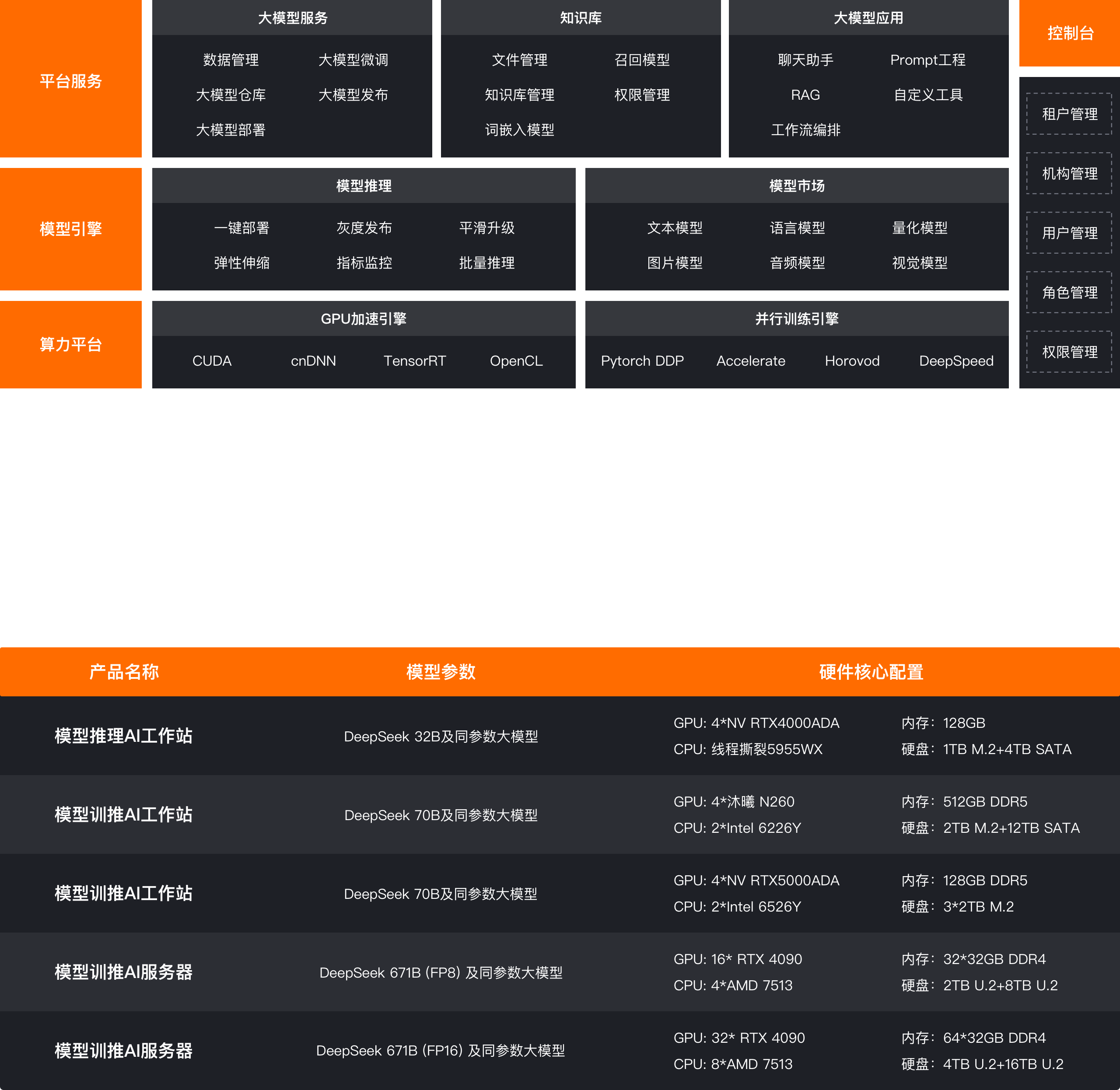
Deep integration of software and hardware, pre-installed optimized driver and O&M toolchain, and deployment can be completed in 10 minutes out of the box. Local privatization deployment ensures zero leakage of core data, supports the setting of different permission roles, manages the addition, deletion, and modification of knowledge and data, and meets the compliance requirements of government, finance, medical and other industries.

The hardware and model can be deeply adapted and optimized. It can customize 8-card GPU clusters, support domestic GPUs, CPUs and other hardware, support domestic operating systems and distributed extensions, and improve inference efficiency by 35% and reduce delay by 40%. It is suitable for all scenarios from stand-alone inference to 100 billion-level parameter training.

Support PDF, Excel, Word and other file types, as well as JPEG, WAV, MP4 and other multi-modal data structured extraction. Integrate OCR, ASR, NLP technology to achieve high-value scenarios such as key contract terms extraction, automatic generation of quality inspection reports, and intelligent summary of meeting minutes.

Provide model pre-training services for vertical scenarios such as government governance, manufacturing quality inspection, medical imaging, etc., support LoRA fine-tuning and knowledge distillation, and improve task accuracy.


The end-to-end chip utilization rate is up to 90%, providing higher measured computing power and supporting INT16 and FP32 operations. Supports 400 users, 100 normal concurrent users, supports hyperscale machine learning, deep learning research and development, hyper-complex simulation and predictive models, and advanced natural language processing tasks.

Provide comprehensive management capabilities of the knowledge base, support automatic and customized configuration of segmentation and cleaning rules, high-precision and low-precision indexing methods, and vector retrieval and full-text retrieval to ensure efficient data processing and accurate information retrieval experience.

Supports the creation and management of Agent applications for intelligent processing of complex business processes. Provides a wealth of configuration options, such as prompts, variable settings, tool components, etc., to support the release of API services, easy to achieve online testing of applications and practical application deployment, greatly reducing the technical threshold and development cycle.

The end-to-end chip utilization rate is up to 90%, providing higher measured computing power and supporting INT16 and FP32 operations. Supports 400 users, 100 normal concurrent users, supports hyperscale machine learning, deep learning research and development, hyper-complex simulation and predictive models, and advanced natural language processing tasks.

Provide comprehensive management capabilities of the knowledge base, support automatic and customized configuration of segmentation and cleaning rules, high-precision and low-precision indexing methods, and vector retrieval and full-text retrieval to ensure efficient data processing and accurate information retrieval experience.

Supports the creation and management of Agent applications for intelligent processing of complex business processes. Provides a wealth of configuration options, such as prompts, variable settings, tool components, etc., to support the release of API services, easy to achieve online testing of applications and practical application deployment, greatly reducing the technical threshold and development cycle.

Traditional medical diagnosis faces challenges such as large amount of image data, low efficiency of manual interpretation, and uneven distribution of expert resources. With the intelligent auxiliary diagnostic system built quickly by the AI all-in-one machine, it can efficiently analyze images and pathological data and generate structured reports, significantly improving diagnostic efficiency. This system precipitates the specialized knowledge base to help grassroots doctors improve the level of diagnosis and treatment. At the same time, it supports multidisciplinary data sharing and meeting consultation coordination, effectively reducing the risk of misdiagnosis, and providing patients with more accurate and efficient medical services.



WeChat Official Account

WeChat Tech Account

Douyin Account

WeChat Group Chat
WeChat Official Account
WeChat Tech Account
Douyin Account
WeChat Group Chat



